Heat maps are great to compare observations with lots of variables (which must be comparable in terms of unit, domain, etc.). In some cases however, traditional heat maps might not suffice, for example when you want to compare multiple groups of observations. One solution is to use facets. Another solution, which I want to explain here, is to make a “ballon plot” with a fixed grid of rows and columns.
In the end we want to create a visualization like in the following image, where there is one observation per row, colored according to a certain group and several variables in the columns. The values themselves are represented as circles (“balloons”) of different sizes.
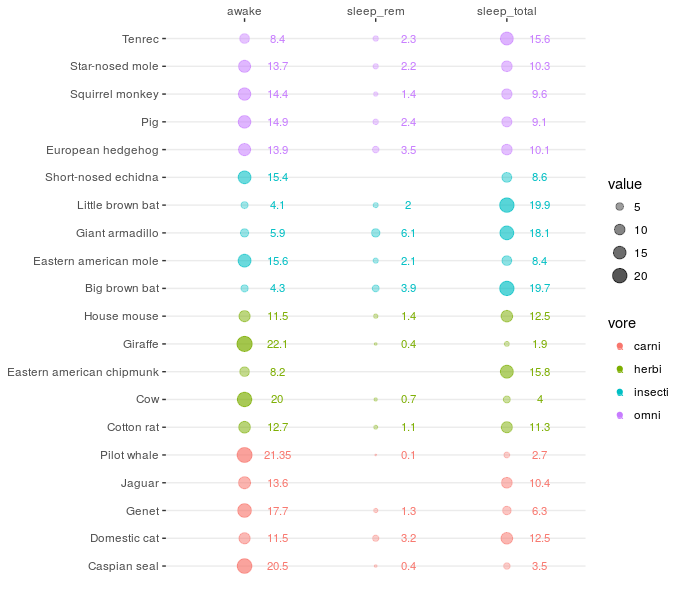
Balloon Plot Example
We will use dplyr and tidyr for data preparation, and ggplot2 for plotting. So let’s import these:
library(dplyr)
library(tidyr)
library(ggplot2)
As an example, we will use the “msleep” dataset which comes with ggplot2. It contains information about sleep of different kinds of mammals:
> head(msleep)
name genus vore order conservation sleep_total sleep_rem sleep_cycle awake brainwt
<chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Cheetah Acinonyx carni Carnivora lc 12.1 NA NA 11.9 NA
2 Owl monkey Aotus omni Primates <NA> 17.0 1.8 NA 7.0 0.01550
3 Mountain beaver Aplodontia herbi Rodentia nt 14.4 2.4 NA 9.6 NA
4 Greater short-tailed shrew Blarina omni Soricomorpha lc 14.9 2.3 0.1333333 9.1 0.00029
5 Cow Bos herbi Artiodactyla domesticated 4.0 0.7 0.6666667 20.0 0.42300
6 Three-toed sloth Bradypus herbi Pilosa <NA> 14.4 2.2 0.7666667 9.6 NA
Each mammal is an observation. We will group it by “vore” (carnivore, omnivore, etc.) so that we can later compare individual mammals and also groups. In the plot, we want these mammals to appear on the y-axis as rows, grouped (i.e. ordered and colored) by the “vore” type.
There are three variables measured in hours which we will compare for our example: awake, sleep_total and sleep_rem. Those will appear in the columns of the plot, hence on the x-axis. Let’s define a character vector with these variables:
vars <- c('awake', 'sleep_total', 'sleep_rem')
Now we need to prepare the data. The most important thing is that we need to convert the “wide” data frame into a “long format”. Each variable awake, sleep_total and sleep_rem will be put into separate rows for each observation. This means that for each observation which makes up exactly one row in the original msleep data set, we will have up to three rows in the new data set. “name” and “vore” will make up the identifier of a single observation. We can use tidyr’s gather() function for this. Let’s have a look at this example:
> gather(msleep[1:3, c('name', 'vore', vars)], key = variable, value = value, -name, -vore)
# A tibble: 9 × 4
name vore variable value
<chr> <chr> <chr> <dbl>
1 Cheetah carni awake 11.9
2 Owl monkey omni awake 7.0
3 Mountain beaver herbi awake 9.6
4 Cheetah carni sleep_total 12.1
5 Owl monkey omni sleep_total 17.0
6 Mountain beaver herbi sleep_total 14.4
7 Cheetah carni sleep_rem NA
8 Owl monkey omni sleep_rem 1.8
9 Mountain beaver herbi sleep_rem 2.4
First, we select the columns we need in a subset of “msleep” (only the first 3 rows), then we use gather() to put all columns from msleep but “name” and “vore” into separate rows. The column names are now in the “variable” column, the value belonging to this observation and variable is in the “value” column.
We use this now for the full “msleep” data set and do some additional data clean up and ordering:
# prepare the data: we use the "msleep" dataset which comes with ggplot2
df <- msleep[!is.na(msleep$vore), c('name', 'vore', vars)] %>% # only select the columns we need from the msleep dataset
group_by(vore) %>% sample_n(5) %>% ungroup() %>% # select 5 random rows from each "vore" group as subset
gather(key = variable, value = value, -name, -vore) %>% # make a long table format: gather columns in rows
filter(!is.na(value)) %>% # remove rows with NA-values -> those will be empty spots in the plot
arrange(vore, name) # order by vore and name
Please note that I only select five random rows per “vore” group here. This is just to provide a reasonable amount of data to plot an example image. With the full number of rows, “overplotting” will occur. So this is one limit of the balloon plot that you should keep in mind: Your data needs to be reduced to a reasonably displayable amount of rows and columns.
Now we have a data frame like this, which is almost ready for plotting:
> head(df)
# A tibble: 6 × 4
name vore variable value
<chr> <chr> <chr> <dbl>
1 Domestic cat carni awake 11.5
2 Domestic cat carni sleep_total 12.5
3 Domestic cat carni sleep_rem 3.2
4 Genet carni awake 17.7
5 Genet carni sleep_total 6.3
6 Genet carni sleep_rem 1.3
The different variables should appear in the columns, so we could set the aesthetic for x to “variable”. The aesthetic for y (the rows of the plot) is generated per name/vore pair. This is not so easy to achieve directly with an ggplot aesthetic, so we need a helper variable called “row”, which we can generate like this:
# add a "row" column which will be the y position in the plot: group by vore and name, then set "row" as group index
df <- df %>% mutate(row = group_indices_(df, .dots=c('vore', 'name')))
Although we could set the aesthetic for x directly to “variable”, as explained before, it’s also good to generate a helper variable “col” for the columns. I noticed that with this, it is easier to set position offsets for the displayed values.
# add a "col" column which will be the x position in the plot: group by variable, then set "col" as group index
df <- df %>% mutate(col = group_indices_(df, .dots=c('variable')))
For both axes, we will need the a character vector of labels (otherwise simply the row/column numbers will be displayed). We can generated them like this:
# get character vector of variable names for the x axis. the order is important, hence arrange(col)!
vars_x_axis <- c(df %>% arrange(col) %>% select(variable) %>% distinct())$variable
# get character vector of observation names for the y axis. again, the order is important but "df" is already ordered
names_y_axis <- c(df %>% group_by(row) %>% distinct(name) %>% ungroup() %>% select(name))$name
Now we finally have all data in order to do the plotting! The most important thing is that we actually make a scatter plot, but with the values distributed across the x and y axes like in a table with rows and columns. Furthermore, we want the size and alpha value of the points in the scatter plot to be dependent on “value” and the color to be dependent on the “vore” group. Hence our aesthetic definition should be aes(x=col, y=row, color=vore, size=value, alpha=value). We make a scatter plot so we’ll use geom_point(). Furthermore, we add a geom_text() with an aesthetic aes(label=value) in order to display the value next to each “balloon”. To finalize the plot, we need to tweak some theme settings and set up the X and Y axes as discrete scales with custom labels. All in all, the plotting command looks like this:
ggplot(df, aes(x=factor(col), y=factor(row), color=vore, size=value, alpha=value)) +
geom_point() + # plot as points
geom_text(aes(label=value, x=col + 0.25), alpha=1.0, size=3) + # display the value next to the "balloons"
scale_alpha_continuous(range=c(0.3, 0.7)) +
scale_size_area(max_size = 5) +
scale_x_discrete(breaks=1:length(vars_x_axis), labels=vars_x_axis, position='top') + # set the labels on the X axis
scale_y_discrete(breaks=1:length(names_y_axis), labels=names_y_axis) + # set the labels on the Y axis
theme_bw() +
theme(axis.line = element_blank(), # disable axis lines
axis.title = element_blank(), # disable axis titles
panel.border = element_blank(), # disable panel border
panel.grid.major.x = element_blank(), # disable lines in grid on X-axis
panel.grid.minor.x = element_blank()) # disable lines in grid on X-axis
The generated plot is clear and readable and even provides the exact numbers to each observation to aid with the problem that circle sizes are hard to interpret in visualizations. It’s easy to add more variables as columns and it would also be possible to flip the x and y axes depending on the layout that you need and the number of rows and columns that you have.
The full R script is available as gist.
Recent Comments