
Together with Clara Bicalho (UC Berkeley) and Sisi Huang (WZB), I recently developed a web application that acts as a convenient interface to the DeclareDesign R package and its repository of research designs, DesignLibrary. This web application, which we called DeclareDesign Wizard, allows users to investigate and customize research designs in their web browser. We used R Shiny for implementing it and since this was my first large Shiny project, I wanted to reflect a bit on the development process and tell in which parts Shiny shone, and in which it didn’t.
Read More →Property based testing for scientific code in Python
Automated software testing starts with the often annoying and time-consuming process of writing tests. But no matter how annoying it is, in the end it always pays off, at least that’s my experience. For this article, I assume that the reader acknowledges the importance of automated software testing, because I would like to point to a way on how to write better tests in less time by using property based testing.
Read More →A Twitter network of members of the 19th German Bundestag – part II

This is the second part about my project that deals with the Twitter network of members of the Bundestag. After getting the necessary data, which was explained in part 1, we will now focus on creating a network graph with links between the representatives’ Twitter accounts for exploratory network analysis.
Read More →A Twitter network of members of the 19th German Bundestag – part I
For the R tutorial that I gave at the WZB in the previous semester, I gave an introduction on how to query web APIs – specifically the Twitter API – and automated data extraction from websites (i.e. web scraping). I showed an example that combined both of these techniques for the goal of getting data about the Twitter activities of members of the current (19th) German Bundestag, which is the federal German parliament. The focus was especially on the question “who follows who” on Twitter. I thought it’s a nice little project showing how to use the Twitter API, do web scraping, combine the collected data and do some exploratory network analysis – all within the R environment. So I decided to polish the code a little bit, put in on GitHub and wrote two blog posts. The first part, i.e. this part, is all about getting the data.
Zooming in on maps with sf and ggplot2

When working with geo-spatial data in R, I usually use the sf package for manipulating spatial data as Simple Features objects and ggplot2 with geom_sf for visualizing these data. One thing that comes up regularly is “zooming in” on a certain region of interest, i.e. displaying a certain map detail. There are several ways to do so. Three common options are:
- selecting only certain areas of interest from the spatial dataset (e.g. only certain countries / continent(s) / etc.)
- cropping the geometries in the spatial dataset using
sf_crop() - restricting the display window via
coord_sf()
I will show the advantages and disadvantages of these options and especially focus on how to zoom in on a certain point of interest at a specific “zoom level”. We will see how to calculate the coordinates of the display window or “bounding box” around this zoom point.
Surveys in oTree with otreeutils
From time to time I’m using oTree as a framework to implement computer-based lab or online experiments for researchers at the WZB. Most experiments include a survey and it’s always quite a hassle to efficiently implement a questionnaire with oTree as its API is mostly designed for more complex things such as multiplayer games and controlled behavioral experiments. For example, for a simple survey question you would need to implement three steps: 1) add a field to the Player model; 2) set up a page and the form fields to display; and 3) set up a template for that page.
I’ve created a Python package named otreeutils (available for installation via pip on PyPI) that contains several utility functions to tackle some of oTree’s deficiencies and it was initially released in November 2016. Since then I added new features from time to time, for example the ability to integrate “custom data models” more easily into oTree, allowing live monitoring and exporting data from such models. I published a short paper that describes how using custom data models and otreeutils helps when trying to collect data of dynamically determined quantity.1
I recently added a new feature to this package that further facilitates creating surveys, especially when using Likert scale inputs. In this post I’m giving a short example on how to use otreeutils for this purpose.
Lab report: Development of school sites in eastern Germany

I wanted to share a small lab report on a project about the development of school sites in eastern Germany since 1992. Rita Nikolai (HU Berlin), Marcel Helbig (WZB) and I published our results a few months ago (see this WZB Discussion Paper or this WZBrief), but I’d like to provide some additional information on the (technical) background in this post as this was not the aim of the mentioned papers.
Checkboxes and crosses: data mining PDFs with the help of image processing
From time to time, I work with “open data” published by public authorities. Often, these data do not deserve the label “open data” and this is mainly because they are provided as PDF files. PDFs are not machine readable, at least not without lot of programming work. I don’t know if this way of publishing data is done on purpose (because authorities are requested to publish open data but they do not want it to be actually analyzed in large scale) or if it is sheer ignorance.
For a recent project I came across a particular nasty type of PDFs: Scores from a school inspection are listed in a large table where each score is marked with a cross (see a full PDF for such a school inspection):

While most data can be extracted from PDF by converting them to a plain text representation, this is not possible for such PDFs. This is because the most important information, the scores, is not existent in the plain text representation of the PDF. The crosses that mark the score are essentially vector-graphics embedded in the PDF. In this article I will explain how to extract such information.
Tools and packages for geospatial processing with Python
In the social sciences, geospatial data appears quite often. You may have social indicators for different places on earth at different administrative levels, e.g. countries, states or municipalities. Or you may study spatial distribution of hospitals or schools in a given area, or visualize GPS referenced data from an experiment. For such scenarios, there’s fortunately a rich supply of open-source tools and packages. As I’ve worked recently quite a lot with geospatial data, I want to introduce some of this software, especially those available for the Python programming language.
Three ways of visualizing a graph on a map
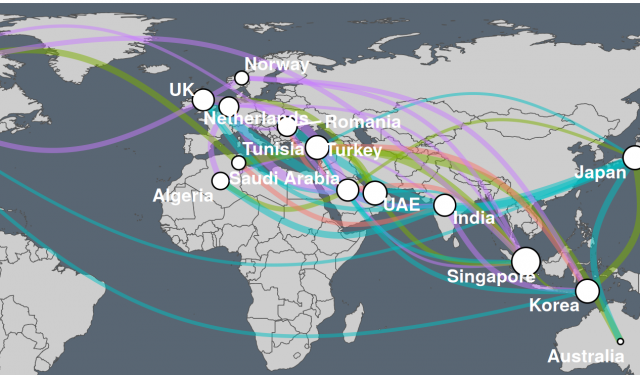
When visualizing a network with nodes that refer to a geographic place, it is often useful to put these nodes on a map and draw the connections (edges) between them. By this, we can directly see the geographic distribution of nodes and their connections in our network. This is different to a traditional network plot, where the placement of the nodes depends on the layout algorithm that is used (which may for example form clusters of strongly interconnected nodes).
In this blog post, I’ll present three ways of visualizing network graphs on a map using R with the packages igraph, ggplot2 and optionally ggraph. Several properties of our graph should be visualized along with the positions on the map and the connections between them. Specifically, the size of a node on the map should reflect its degree, the width of an edge between two nodes should represent the weight (strength) of this connection (since we can’t use proximity to illustrate the strength of a connection when we place the nodes on a map), and the color of an edge should illustrate the type of connection (some categorical variable, e.g. a type of treaty between two international partners).
Recent Comments