When doing text processing with NLTK on large corpora, you often need a lot of patience since even simple methods like word tokenization take quite some time when you’re processing a large amount of text data. This is because NLTK does not often harness the power of modern multicore computers — the code will only run on a single core even if you have four processing cores in your machine. You will need to add parallel processing of your documents yourself. Fortunately this is quite straight forward to implement with Python’s multiprocessing module and I will show how to do this in this small post.
Lemmatization of German language text
Lemmatization is the process of finding the base (or dictionary) form of a possibly inflected word — its lemma. It is similar to stemming, which tries to find the “root stem” of a word, but such a root stem is often not a lexicographically correct word, i.e. a word that can be found in dictionaries. A lemma is always a lexicographically correct word.
When using text mining models that depend on term frequency, such as Bag of Words or tf-idf, accurate lemmatization is often crucial, because you might not want to count the occurrences of the terms “book”, and “books” separately; you might want to reduce “books” to its lemma “book” so that it is included in the term frequency of “book”.
For English, automatic lemmatization is supported in many Python packages, for example in NLTK (via WordNetLemmatizer) or spaCy. For German, however, I could only find the CLiPS pattern package which has limited use (e.g. it cannot handle declined nouns) and is not supported in Python 3. By using the annotated TIGER corpus of the University of Stuttgart, I will try to measure the accuracy of a lemmatizer based on the pattern.de module and will suggest an improved lemmatizer which improves pattern.de’s accuracy by about 10%.
Interactive Balloon Charts with d3-balloon

As explained before, balloon plots can be a good way to compare many observations with lots of variables. I have now created a small extension for d3.js v4 that allows to implement interactive balloon charts quite easily. It is available on GitHub and can be seen live in action for a recent news article about segregation in schools on the WZB website.
Using Django with an existing legacy database
The Django web framework is well suited for creating medium sized research databases. It allows rapid development of a convenient data administration backend (using the Django Admin Site) as well as appealing frontends for published data (as done in the LATINNO project at the WZB). This works well when you build a database from ground up by defining model classes at first and then let Django generate the database schema itself (Django models → Database schema). Often enough however, it is necessary to revise an existing database or at least the data administration interface. In this scenario, the database schema is already defined and hence it is necessary to create Django models from the schema (Database schema → Django models). Django can handle this situation pretty well but some advises have to be followed which I’ll explain here.
Data Mining OCR PDFs — Using pdftabextract to liberate tabular data from scanned documents

During the last months I often had to deal with the problem of extracting tabular data from scanned documents. These documents included quite old sources like catalogs of German newspapers in the 1920s to 30s or newer sources like lists of schools in Germany from the 1990s. All sources were of mixed scanning quality (including rotated or skewed pages) and had very different table layouts. Some had visible table column borders, others only table header borders so the actual table cells were only visually separated by “white-space”. Automated data extraction with tools from ABBYY or using Tabula failed in most cases. Because of the big variety of scanning quality and table layouts, a general single-solution approach didn’t work out. Hence I created a set of common tools that allow to detect table layouts on scanned pages in OCR PDFs, enable visual verification of the detected layouts and finally allow the extraction of the data in the tables. To detect and extract the data I created a Python library named pdftabextract which is now published on PyPI and can be installed with pip. The detected layouts can be verified page by page using pdf2xml-viewer. This post will cover an introduction to both tools by showing all necessary steps in order to extract tabular data from an example page. The necessary files can be found in the examples directory of the pdftabextract github repository. A Jupyter Notebook for this example is also available there.
Creating a “balloon plot” as alternative to a heat map with ggplot2
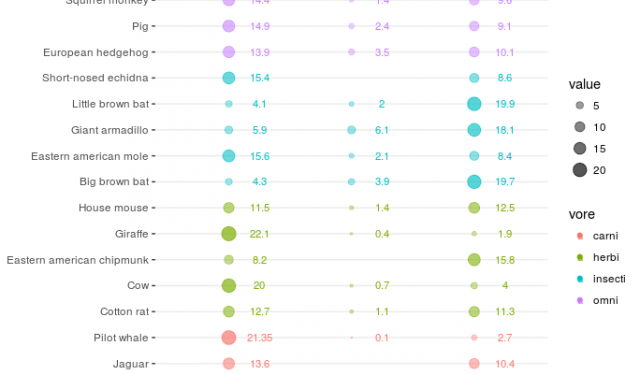
Heat maps are great to compare observations with lots of variables (which must be comparable in terms of unit, domain, etc.). In some cases however, traditional heat maps might not suffice, for example when you want to compare multiple groups of observations. One solution is to use facets. Another solution, which I want to explain here, is to make a “ballon plot” with a fixed grid of rows and columns.
otreeutils – A package with common oTree utility/helper functions and classes
As a little side product from the experiments that I recently implemented with oTree, I created otreeutils. This package contains several utility functions and classes for use cases that I came across quite often in the recent weeks. So I decided to create this small package to re-use my code in several experiments and also to share it with others. Update: The package is now also available on PyPI. You can install it via pip install otreeutils.
First and foremost, otreeutils allows easier creation of surveys, which are a part of many experiments. Instead of defining the Player model fields, the view page(s) and HTML templates separately, it’s now possible to define the survey questions and their fields in a single data structure. Then you can generate the Player model class automatically and just define the order of survey pages (if you distribute the survey questions across several pages) — no need to write any HTML.
Another use case that occurs quite often are pages with understanding questions. The participant can only proceed after answering a set of understanding questions correctly. Hints can be displayed for wrong answers. This is implemented in the UnderstandingQuestionsPage base class. Again, the questions can be defined in a single data structure, no template needs to be edited.
Finally, we found that we needed a softer variant of oTree’s page timeouts, which automatically switch to the next page after a time limit. I implemented a small extension that allows to define a “timeout warning” which is displayed after the time limit is reached. The participant is not forced to the next page.
More features might come soon as we continue to use oTree at the WZB.
The github repository explains the API in the README file and contains fully documented example apps.
Using custom data models in oTree
I’m currently working on implementing some multiplayer decision strategy games for different experiments in the field of Experimental Economics. We decided to use the excellent oTree framework as basis for our implementations. Since oTree itself is based on Django and provides comprehensive documentation and some good tutorials, it was quite straight forward for me to learn. In most cases, it provides just what you need for implementing an experiment while hiding a lot of unnecessary technical stuff by exposing only a limited API. The full power and functionality of Django is hidden to the programmer for the sake of clearness and simplicity, which is basically a good thing.
However, in some cases oTree’s API is too restrictive for implementing advanced functionality, the main issue being the limited set of data models: By default, you can only record non-complex information (i.e. numeric values, strings, etc.) per subsessions (i.e. round), group or player. What if you need, for example, to record an arbitrary number of (more or less complex) decisions made by a player per round? This is not really supported by oTree’s data models so you need to define and handle your own, custom Django models. I will explain how to do this in this post.
Styling individual cells in Excel output files created with pandas
The Python Data Analysis Library pandas provides basic but reliable Excel in- and output. However, more advanced features for writing Excel files are missing. Some of these advanced things, like conditional formatting can be achieved with XlsxWriter (see also
Improving Pandas’ Excel Output). However, sometimes it is
necessary to set styles like font or background colors on individual cells on the “Python side”. In this scenario,
XlsxWriter won’t work, since “XlsxWriter and Pandas provide very little support for formatting the output data from a dataframe apart from default formatting such as the header and index cells and any cells that contain dates of datetimes.”
To achieve setting styles on individual cells on the Python side, I wrote a small extension for pandas and put it on github, along with some examples. It comes in quite handy, for example when you are running complicated data validation routines (which you probably don’t want to implement in VBA) and want to highlight the validation results by coloring
individual cells in the output Excel sheets.
Parallel Coordinate Plots for Discrete and Categorical Data in R — A Comparison
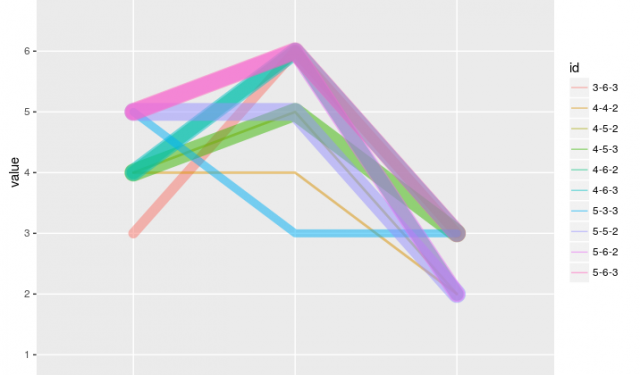
Parallel Coordinate Plots are useful to visualize multivariate data. R provides several packages/functions to draw Parallel Coordinate Plots (PCPs):
- ggparcoord in the package GGally
- the package ggparallel
- plain ggplot2 with geom_path
In this post I will compare these approaches using a randomly generated data set with three discrete variables.
Recent Comments